优化 Skill 的描述
通过改进Skill 的描述,使其能够被更稳定地触发
一个 Skill 写得再好,如果没有被触发使用,其实是没有意义的。 而决定它会不会被用到的关键,就是 SKILL.md 里的 description(描述字段)。
Agent 就是靠这段描述来判断:当前任务要不要用这个 Skill。
Skill 是如何被触发的
Agent 在处理任务时,会采用一种“按需加载”的方式来管理上下文。
一开始,它只会读取每个 Skill 的名称和描述,用来快速判断: 哪些 Skill 可能和当前任务有关
只有当用户的任务和某个描述匹配,满足触发条件时,Agent 才会进一步:
- 把完整的 SKILL.md 加载进来
- 并按照里面的指令执行
这也就意味着:description 承担了“是否触发”的全部责任。如果描述没有说清楚这个 Skill 在什么情况下有用,Agent 就不会意识到要使用它。
还有一个容易被忽略的点:Agent 通常只会在自己搞不定的任务时,才会去找 Skill。
像是“读取README.md”这种简单任务,即使有对应 Skill,也通常不会触发,因为 Agent 自己就能完成
如何写好一个 description
用“指令”而不是“介绍“的方式来写
不要写成介绍说明(比如“这个 Skill 可以做什么”),而要写成对 Agent 的指令:用「在什么情况下使用这个 Skill」来表达。
例如:
- ❌ 这个 Skill 用于处理数据分析
- ✅ 当用户需要进行数据分析时,使用这个 Skill
因为 Agent 面临的是一个“要不要用”的决策,你需要直接告诉它什么时候该用。
关注用户意图,而不是实现细节
不要描述 Skill 内部是怎么做的,而要描述:用户想达成什么目标。 因为 Agent 是根据用户的问题来匹配的,而不是根据你的实现方式。
所以重点写“用户想做什么”,而不是“这个 Skill 怎么实现”。
例如:
- ❌ 当用户需要使用 pandas 进行数据处理,并生成统计结果时,使用这个 Skill。
- ✅ 当用户需要分析数据、总结规律、或从数据中提取结论时,使用这个 Skill。
宁错勿漏
可以明确列出各种适用场景,甚至包括一些用户没有直接说出来的情况。不要期望用户会说的非常精准, 用户的表达可能千差万别,我们要做的是尽可能“主动“一点,宁可多触发,也别漏掉。
比如:即使用户没有明确提到 ‘CSV’ 或 ‘数据分析’,但只要是在做数据分析的任务,也应该使用这个 Skill
设计触发测试用例
为了验证一个 Skill 能不能在合适的时候被触发,我们可以准备一组测试用的用户输入(eval queries)。
每条测试输入都要明确指出这条该请求“应该触发”还是“不应该触发”这个 Skill,比如:
[
{
"query": "我有一份销售数据表,能帮我算一下利润率并标出低于10%的吗?",
"should_trigger": true
},
{
"query": "怎么把 json 文件转成 yaml?",
"should_trigger": false
}
]一般来说,准备大约 20 条左右比较合适, 大致对半分成“应该触发”和“不应该触发”两类。
“应该触发”的测试要怎么设计
这一类用来验证:你的 description 是否真的覆盖了 Skill 的使用范围。
可以从几个维度去“刻意变化”:
1. 表达方式
不要都写得很标准,要混合:
- 正式表达
- 口语表达
- 甚至带错别字、缩写
关键是要模拟真实用户,而不是我们脑子里的理想用户
2. 是否说得很明确
有些用户会直接说:“帮我分析这个 CSV”,但更多时候是: “老板让我根据这份数据做个图”
核心是要覆盖这种没点名,但本质一样的需求
3. 信息可多可少
同一个任务,用户可能用“很短一句话”表达,也可能给出一大段背景信息。这两种情况都要覆盖。 如果只测试一种,很容易误判 Skill 的触发效果,所以要混合:
- 很简短的请求(如“一句话需求”)
- 很详细的描述(带路径、字段、背景等)
测试 Skill 在不同信息密度下的表现
比如:
帮我分析一下销售数据,做个图。我在做 Q4 复盘,有一份数据在 ~/data/q4_sales.xlsx。
C 列是收入,D 列是成本。老板特别关注利润率低于 15% 的产品,
你能帮我算一下利润率,并标出异常项,再做一张趋势图吗?4. 任务复杂度
用户可能说:“帮我分析这份销售表”,也可能说:“我下周要给管理层做季度复盘。请你先看一下这份销售数据,找出收入下滑的原因,再整理成汇报提纲,最后帮我写一版演讲稿。”
后一种情况其实包含多个步骤:
- 看销售数据
- 找出收入变化原因
- 整理汇报提纲
- 写演讲稿
其中真正需要“数据分析 Skill”的,可能只是第 1、2 步,但它被包在一个更大的任务链里了。
所以测试时要看:
Agent 能不能识别出:虽然用户没有单独说“使用数据分析 Skill”,但这个复杂任务里有一部分确实需要它。
5. 隐性匹配优先
在测试时,最有价值的“应该触发”用例,不是那种一眼就能看出来的,而是:这个 Skill 确实有用,但从用户的话里不那么明显能看出来。
这种情况下,description 写得好不好就会直接影响是否触发。
因为如果用户已经说得非常直接(比如刚好就是 Skill 做的那件事),那基本任何正常的 description 都能触发,测试意义不大。而真正能检验质量的,是这些情况:Skill 能帮上忙,但需要 Agent“理解一下”才能联想到。
“不应该触发”的测试
最有价值的负面测试,不是那些完全无关的请求,而是: “差一点就匹配上”的情况(near-miss)
也就是:
- 表面上看起来很像
- 有相似的关键词或概念
- 但实际上需要的是另一种能力
这种测试用来检验: 你的 description 是不是“精准”,而不只是“范围很大”。
什么是“无效”的负面测试?
比如一个 CSV 数据分析的 Skill:
- 写一个斐波那契函数 (概念完全不相关)
- 怎么做蛋炒饭 (没有任何关键词重叠)
这些测试都太“明显“无关了,基本上没有测试意义。
什么是“强”的负面测试?
- 我需要修改 Excel 预算表里的公式 (有“表格”“数据”这些关键词,但任务是“编辑 Excel”,不是“分析 CSV”)
- 能帮我写个 Python 脚本,把 CSV 表格里的每一行导入到 Postgres 吗? (涉及 CSV和表格, 但任务是“写脚本”,不是“分析数据”)
这类测试的价值在与它会“迷惑”Agent,逼它做出更精确的判断。
让测试更真实
真实用户的表达,往往比测试用例复杂得多。建议在测试用例中刻意加入:
- 文件路径:比如:~/Downloads/report_final_v2.xlsx;
- 个人背景:比如:“我老板让我……”;
- 具体细节:比如:列名、公司名、具体数据;
- 自然语言特征:比如:口语、缩写、甚至一点错别字。
如何测试
最基本的方法是:把每一条测试用例都交给 Agent 运行一遍,然后观察 这个 Skill 有没有被调用。
怎么判断有没有触发?
大多数 Agent 都提供一些“可观察信息”,比如:
- 执行日志
- 工具调用记录
你可以通过这些信息判断:
- ✅ 如果 Agent 加载了这个 Skill 的 SKILL.md → 说明触发了
- ❌ 如果完全没有用到 → 说明没有触发
怎样算测试通过?
前面我们提到过,每套测试用例里,都用 should_trigger 字段明确了每条用例的预期结果。所以
- 如果:should_trigger = true 且 Skill 被调用 → ✅ 通过
- 如果:should_trigger = false 且 Skill 没被调用 → ✅ 通过
否则就算失败。
多跑几次
模型的输出有一定的随机性,所以建议每条测试用例多跑几次,观察触发率。如果某条用例的触发率很低(比如只有 20%),那就说明这个 description 可能写得不够好,需要优化。
如何判断是否通过?
可以设一个阈值(比如 0.5就是一个合理的阈值):
- 对于“应该触发”的 query: 触发率 > 0.5 → ✅ 通过
- 对于“不应该触发”的 query: 触发率 < 0.5 → ✅ 通过
如何避免“过拟合”
什么是“过拟合”呢?简单来说就是:你学会了“题目本身”,而不是“解题方法”。
举个例子:
假设你在准备考试,你把历年真题的答案全背下来, 这样的问题是考试一旦换了题目,就不会做了。这就是过拟合。
正确的方式是:你理解了解题思路和方法,这样即使题目换了,也能应对。
为避免“过拟合“的情况,建议把测试数据分成两部分:
- 训练集(Train,约 60%):用来发现问题、不断修改 description
- 测试集(Test,约 40%):保留不用,只在最后用来验证
将数据分为“训练集“和“测试集“的时候,一定要确保测试用例要布均衡,两边都要包含“应该触发”和“不应该触发”的用例。
不要出现训练集全是正例,验证集全是反例(反之亦然)这种情况,否则测试结果会失真。
实操建议
- 先把所有测试用例随机打乱
- 然后按比例拆分
- 并且在后续迭代中保持这个划分不变
优化流程
Skill 的 description 优化,是一个不断试错、调整的过程。 你可能需要反复修改 description,才能找到那个既能覆盖所有“应该触发”的情况,又能避免“不应该触发”的情况的最佳版本。
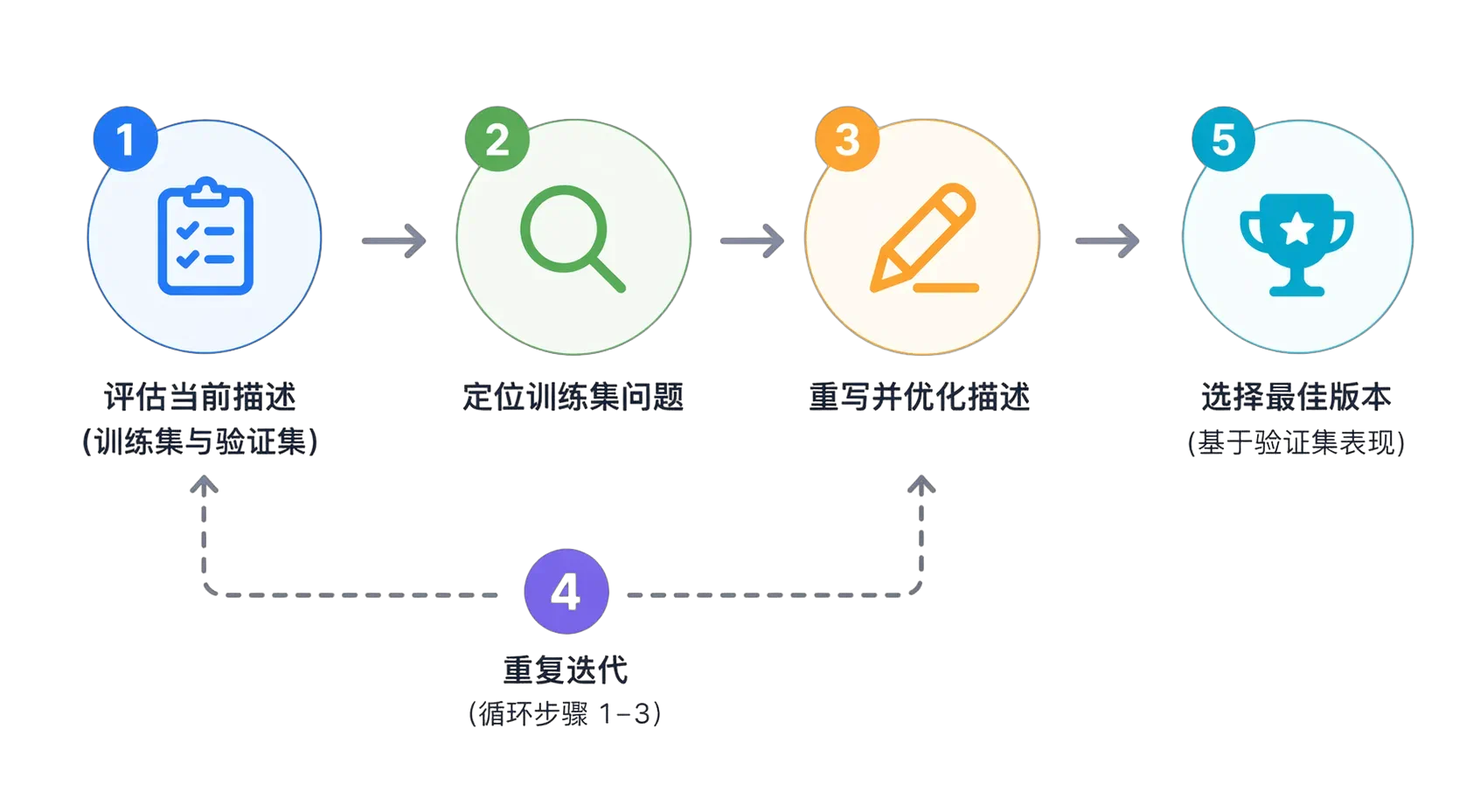
针对问题,重写描述
注意这里的调整是提升泛化能力,而不是修补个别case,不然修修补补,补上了这个 case,又漏了那个 case,始终过不了验证集。
该触发却没触发 → 描述可能太窄
可能原因:覆盖范围不够、使用场景没说清
调整方式:
- 扩大适用范围
- 补充“什么时候应该用这个 skill”的上下文
不该触发却触发了 → 描述可能太宽
可能原因:边界不清、定义模糊
调整方式:
- 明确这个 skill 不做什么
- 划清它与相似能力之间的边界
避免“关键词打补丁”
有时候图省事,我们倾向于直接把失败案例里的关键词写进描述里。
更好的做法:
- 抽象出这些失败案例背后的“类别”或“意图”
- 从概念层面补齐,而不是补词
多次迭代无果 → 换结构,而不是微调
如果连续几轮小修小补都效果不明显,就要放弃再做局部优化。因为很有可能是表达方式或结构本身的问题了,这时候就要大胆换一种说法,或者换一个结构了。
例如:
- 从“功能描述”改成“使用场景驱动”
- 或从“定义式”改为“边界式描述”
控制长度:不要无限膨胀
优化过程中描述很容易越写越长,始终注意:
- 保持在 1024 字符限制以内
- 避免为了覆盖所有情况而堆砌细节
用验证集选“最好版本”,而不是最后版本
最终选择描述时:
- 看的是验证集通过率
- 选“泛化最好”而不是最后的版本
注意:
- 最优版本不一定是最后一次修改
- 后期版本可能已经开始“过拟合训练集”,反而在验证集上变差
关于迭代次数的经验判断
一般来说 5 轮左右就足够。
如果反复优化仍然没有提升,问题可能不在描述,而在数据本身:
- 数据太简单(没有区分度)
- 数据太难(模型无法覆盖)
- 测试用例的标注本身有问题(对错定义不清)
这时应该回头检查数据,而不是继续改描述。